Có nhiều thuật toán khác nhau được sử dụng để nhận dạng chữ viết tay trong thị giác máy tính, tùy thuộc vào mục đích và độ chính xác cần thiết. Dưới đây là một số ví dụ về các thuật toán này:
1. K-Nearest Neighbors (KNN):
Thuật toán này xác định lớp của một điểm dữ liệu mới bằng cách so sánh nó với k điểm dữ liệu gần nhất trong tập huấn luyện, sau đó đưa ra dự đoán dựa trên lớp phổ biến nhất trong số k điểm này.
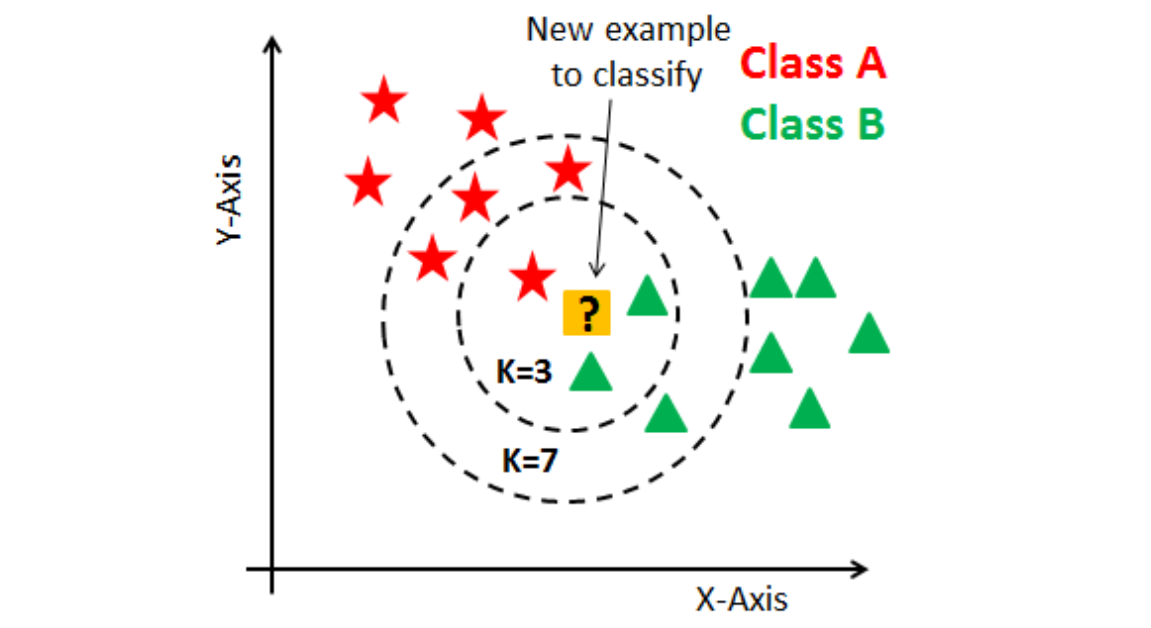
Thuật toán K-Nearest Neighbors (KNN) là một thuật toán học có giám sát sử dụng để phân loại các đối tượng dựa trên các ví dụ giống nhau đã được gán nhãn. Cụ thể, thuật toán này sử dụng khoảng cách Euclid để tính toán khoảng cách giữa các điểm dữ liệu, sau đó dùng các điểm dữ liệu gần nhất để phân loại các điểm dữ liệu mới.
Các bước để thực hiện thuật toán KNN như sau:
- Tính khoảng cách Euclid giữa điểm dữ liệu mới và các điểm dữ liệu cũ đã được gán nhãn.
- Chọn k điểm gần nhất từ tập dữ liệu đã được gán nhãn.
- Phân loại điểm dữ liệu mới bằng cách sử dụng phương pháp "đa số bầu chọn", trong đó điểm dữ liệu mới được gán nhãn bằng nhãn xuất hiện nhiều nhất trong k điểm gần nhất.
Thuật toán KNN có ưu điểm là đơn giản và dễ hiểu, đồng thời có khả năng phân loại tốt đối với các tập dữ liệu có kích thước lớn. Tuy nhiên, nó cũng có một số nhược điểm, bao gồm độ phức tạp tính toán tăng lên khi số lượng điểm dữ liệu lớn, và khó khăn trong việc định nghĩa số k tốt nhất để sử dụng cho việc phân loại.
2. Support Vector Machine (SVM):
Thuật toán này tìm kiếm siêu phẳng tốt nhất để phân tách các lớp trong không gian đặc trưng. Khi một điểm mới được đưa vào, nó được gán vào lớp tương ứng dựa trên vị trí của nó liên quan đến siêu phẳng.
Support Vector Machine (SVM) là một thuật toán học có giám sát trong Machine Learning. SVM là phương pháp tìm một siêu phẳng trong không gian dữ liệu, chia tập dữ liệu thành hai lớp khác nhau.
Thuật toán SVM hoạt động bằng cách tìm ra siêu phẳng tốt nhất để phân loại dữ liệu thành hai lớp khác nhau. Siêu phẳng này là siêu phẳng có khoảng cách xa nhất giữa các điểm dữ liệu của hai lớp. Các điểm dữ liệu gần siêu phẳng được gọi là các vector hỗ trợ. SVM sử dụng các vector hỗ trợ để xác định siêu phẳng tốt nhất.
Các bước để xây dựng một SVM bao gồm:
- Chuẩn bị dữ liệu huấn luyện.
- Chọn một hàm kernel (linear, polynomial, radial basis function, sigmoid) để chuyển dữ liệu vào không gian chiều cao hơn nếu cần thiết.
- Xây dựng mô hình SVM bằng cách tìm siêu phẳng tốt nhất để phân loại dữ liệu thành hai lớp.
- Đánh giá hiệu suất của mô hình bằng cách sử dụng tập dữ liệu kiểm tra.
SVM có ưu điểm là có thể xử lý các bài toán phân loại phức tạp, đặc biệt là khi có số lượng lớn các tính năng (features) và dữ liệu đa chiều. Tuy nhiên, SVM có thể trở nên phức tạp và tốn kém về mặt tính toán với các tập dữ liệu lớn.
3. Multi-Layer Perceptron (MLP):
Đây là một loại mạng nơ-ron nhân tạo với nhiều lớp ẩn. Thuật toán này học các đặc trưng của chữ viết tay thông qua việc tối ưu hóa hàm mất mát, sau đó sử dụng mô hình đã học để phân loại chữ viết tay mới.
Multi-Layer Perceptron (MLP) là một kiểu mạng nơ-ron truyền thống, bao gồm nhiều lớp ẩn giữa lớp đầu vào và lớp đầu ra. Mỗi lớp có nhiều đơn vị xử lý (neuron) kết nối với lớp kế tiếp bằng các trọng số có thể điều chỉnh được.
Mục tiêu của MLP là tìm ra trọng số tối ưu giữa các lớp sao cho kết quả đầu ra của mạng phù hợp nhất với các dữ liệu huấn luyện. Việc huấn luyện MLP thường được thực hiện bằng các thuật toán như Gradient Descent, Backpropagation, hoặc Levenberg-Marquardt.
MLP được ứng dụng rộng rãi trong nhiều bài toán như nhận dạng ảnh, phân loại văn bản, dự báo tài chính, và nhiều lĩnh vực khác.
Multi-Layer Perceptron (MLP) là một kiến trúc mạng nơ-ron nhân tạo gồm nhiều tầng ẩn, được sử dụng để giải quyết các bài toán phân loại và hồi quy.
Để xây dựng một mô hình MLP, ta thực hiện các bước sau:
- Thu thập dữ liệu: Thu thập và chuẩn bị dữ liệu để sử dụng cho việc huấn luyện mô hình.
- Tiền xử lý dữ liệu: Xử lý dữ liệu để chuẩn hóa và tạo đặc trưng phù hợp cho mô hình.
- Chia tập dữ liệu: Phân chia dữ liệu thành tập huấn luyện và tập kiểm tra, để đánh giá hiệu quả của mô hình.
- Xây dựng kiến trúc mô hình: Xác định số lượng tầng ẩn và số lượng nơ-ron trong mỗi tầng ẩn.
- Khởi tạo trọng số: Khởi tạo trọng số ngẫu nhiên cho các liên kết giữa các nơ-ron trong mô hình.
- Huấn luyện mô hình: Sử dụng thuật toán lan truyền ngược để huấn luyện mô hình trên tập dữ liệu huấn luyện. Quá trình huấn luyện sẽ cập nhật trọng số của mô hình để giảm thiểu sai số dự đoán.
- Đánh giá mô hình: Sử dụng tập kiểm tra để đánh giá hiệu quả của mô hình.
- Điều chỉnh mô hình: Nếu mô hình không đạt được hiệu quả mong muốn, ta có thể thay đổi kiến trúc mô hình hoặc thử các giá trị khác cho các siêu tham số để cải thiện hiệu suất của mô hình.
- Sử dụng mô hình: Sau khi đạt được hiệu quả mong muốn trên tập kiểm tra, ta có thể sử dụng mô hình để dự đoán trên dữ liệu mới.
4. Convolutional Neural Network (CNN):
Thuật toán này sử dụng các lớp tích chập để học các đặc trưng của chữ viết tay. Các lớp tích chập này giúp giảm số lượng tham số cần tối ưu hóa và tăng tính tổng quát của mô hình. Sau khi học các đặc trưng, một hoặc nhiều lớp kết nối đầy đủ được sử dụng để phân loại chữ viết tay.
Convolutional Neural Network (CNN) là một trong những thuật toán quan trọng trong lĩnh vực học sâu và thị giác máy tính. Nó được sử dụng rộng rãi trong các bài toán liên quan đến xử lý hình ảnh, bao gồm nhận dạng đối tượng, phân loại ảnh, phát hiện khuôn mặt, xử lý video và nhiều ứng dụng khác.
CNN được thiết kế để học cách rút trích các đặc trưng của dữ liệu hình ảnh. Nó có thể tự động học các đặc trưng của ảnh, bao gồm các cạnh, góc, màu sắc, texture, v.v. Sau đó, nó sử dụng các đặc trưng này để phân loại các ảnh hoặc thực hiện các tác vụ khác trên ảnh.
Một CNN thường bao gồm các lớp sau:
- Lớp đầu vào (input layer): lớp này chứa các giá trị đầu vào, thường là các ảnh được mã hóa dưới dạng ma trận.
- Lớp tích chập (convolutional layer): lớp này sử dụng các bộ lọc để trích xuất các đặc trưng của ảnh. Các bộ lọc này di chuyển trên toàn bộ ảnh và tạo ra các đặc trưng tương ứng với vị trí của nó trên ảnh.
- Lớp pooling (pooling layer): lớp này được sử dụng để giảm kích thước của đầu ra của lớp tích chập và giảm số lượng tham số cần học.
- Lớp kích hoạt (activation layer): lớp này áp dụng một hàm kích hoạt để tạo ra đầu ra của một nơ-ron.
- Lớp đầy đủ kết nối (fully connected layer): lớp này được sử dụng để kết nối tất cả các đặc trưng được trích xuất từ ảnh với tầng đầu ra.
- Lớp đầu ra (output layer): lớp này chứa các giá trị đầu ra, thường là các xác suất được dự đoán cho từng lớp.
CNN được đào tạo bằng cách sử dụng các thuật toán như backpropagation và stochastic gradient descent để tối ưu hóa các tham số của mô hình. Các tham số này bao gồm các bộ lọc và trọng số của mạng. Khi được huấn luyện đầy đủ, CNN có thể nhận dạng và phân loại các ảnh với độ chính.
Đây là các bước cơ bản để xây dựng một mô hình CNN:
- Chuẩn bị dữ liệu: Đây là bước quan trọng nhất, vì một mô hình tốt chỉ có thể được xây dựng trên dữ liệu tốt. Dữ liệu cần được chuẩn bị và tiền xử lý sao cho phù hợp với mô hình CNN.
- Xây dựng mô hình: Có nhiều phương pháp khác nhau để xây dựng mô hình CNN, nhưng phương pháp phổ biến nhất là sử dụng các lớp Convolutional, Pooling và Fully Connected để tạo ra một kiến trúc CNN hoàn chỉnh.
- Huấn luyện mô hình: Sau khi xây dựng mô hình CNN, ta cần huấn luyện nó với dữ liệu đã chuẩn bị trước đó. Việc này thường được thực hiện bằng cách sử dụng các phương pháp tối ưu hóa như Gradient Descent để cập nhật các trọng số của mô hình.
- Đánh giá mô hình: Sau khi mô hình được huấn luyện, ta cần đánh giá chất lượng của nó trên các tập dữ liệu riêng biệt. Các phương pháp đánh giá thường được sử dụng bao gồm độ chính xác (accuracy), ma trận nhầm lẫn (confusion matrix), và các phép đo khác.
- Tinh chỉnh mô hình: Nếu mô hình không cho kết quả tốt, ta có thể tinh chỉnh nó bằng cách thay đổi kiến trúc hoặc các siêu tham số (hyperparameters) như tốc độ học, số lượng lớp, số lượng bộ lọc, kích thước bộ lọc, v.v.
- Sử dụng mô hình: Cuối cùng, sau khi mô hình đã được huấn luyện và tinh chỉnh, ta có thể sử dụng nó để phân loại các hình ảnh mới hoặc thực hiện các tác vụ khác trong lĩnh vực Thị giác máy tính.
Các thuật toán này đều có những ưu điểm và hạn chế riêng, và tùy thuộc vào tình huống cụ thể mà một thuật toán có thể phù hợp hơn các thuật toán khác.